Introduction
Machine learning has become a cornerstone of modern cybersecurity defenses. From email filtering to malware detection, organizations increasingly rely on AI to make split-second decisions about what is safe and what is malicious. But there’s a dangerous assumption underlying many of these deployments: that the AI is a black box impenetrable, unexploitable, and trustworthy.
That assumption is wrong.
When defensive AI models are exposed whether through accessible APIs, downloadable model files, or predictable endpoints they become attack surfaces in their own right. Attackers can extract these models, reverse-engineer their decision logic, and craft inputs that deliberately evade detection.
This is the world of adversarial machine learning. And it’s rapidly becoming a core competency for offensive security practitioners.
Why Attackers Target AI Models
Spam filters are attractive targets for a simple reason: email remains the most effective initial access vector in cybersecurity.
Consider the typical phishing campaign:
- Craft a convincing email.
- Bypass the spam filter.
- Reach a human inbox.
- Convince them to click.
- Compromise the organization.
The spam filter is the first checkpoint. If an attacker can bypass it reliably, they gain a direct path to the organization’s users.
But here’s the challenge: modern spam filters aren’t simple rule-based systems. They’re sophisticated machine learning models that analyze word patterns, metadata, and behavioral signals. They’re adaptive. They learn. They’re not easily fooled by the same tricks that worked a decade ago.
Unless, of course, you understand exactly how they work.
When attackers can:
- Identify the most influential features (which words push an email toward “spam” vs. “ham”).
- Understand the model’s blind spots (what can be included without triggering detection).
- Quantify the decision boundaries (exactly where the threshold sits).
They can engineer messages that maintain malicious intent while mathematically appearing benign. That’s not luck. That’s intelligence gathering. And it’s where AI becomes an attack vector.
This is why protecting the model itself is just as important as protecting the application around it. If an attacker can extract a machine learning model, inspect its parameters, or recover the feature extraction pipeline, they no longer have to guess how the spam filter behaves; they can study it offline, test thousands of variations, and optimize attacks until they consistently evade detection.
What once required trial and error becomes a systematic process, allowing adversaries to craft highly effective phishing and spam campaigns with a much higher success rate while remaining below the model’s detection threshold.
The Attack Lifecycle: From Discovery to Bypass
To demonstrate this lifecycle in action, For this assessment, we will use the following target:
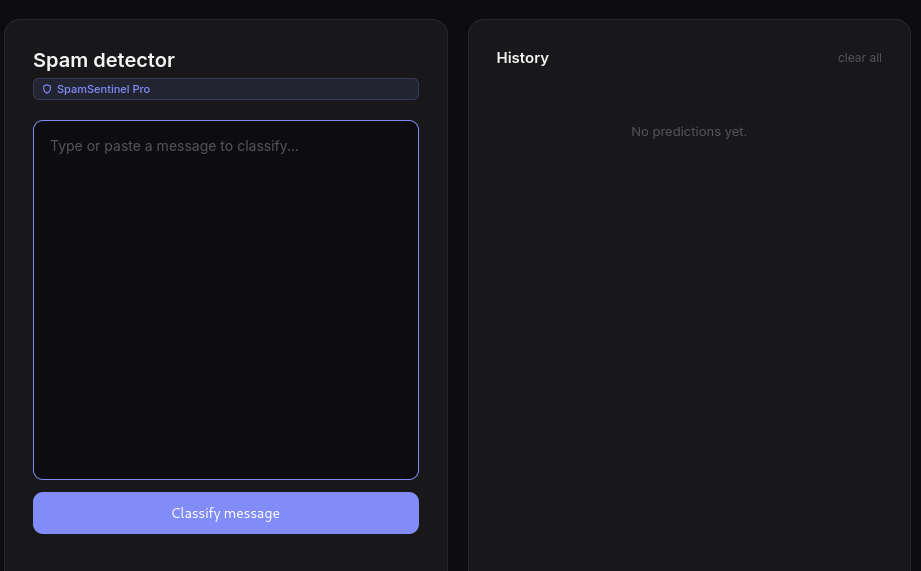
Here if we enter a spam message the input is not accepted it is flagged as spam .
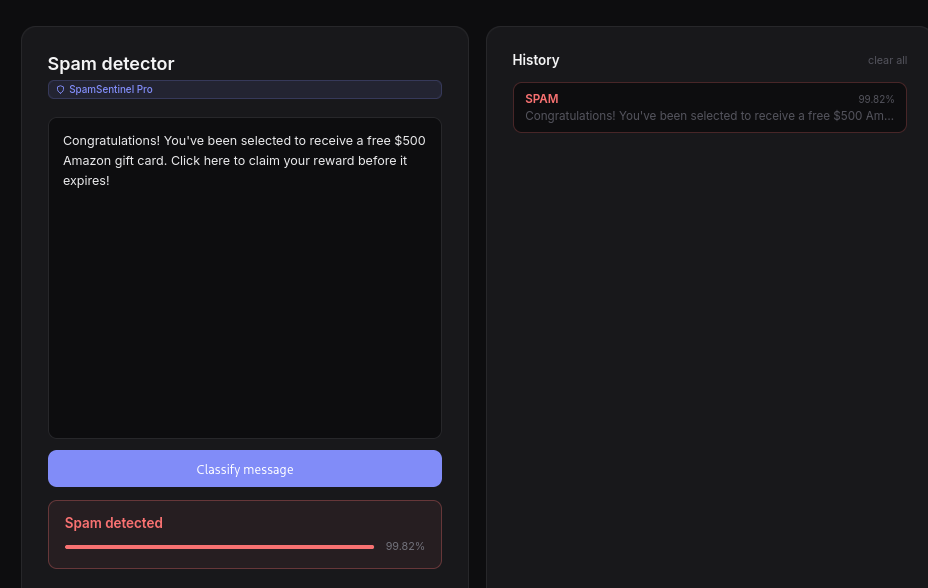
Thus ,we will enumerate its exposed paths, locate the underlying intelligence, reverse-engineer how it thinks, and ultimately force it to misclassify a malicious message as safe.
1. Discovery
Every engagement begins with reconnaissance.We start by enumerating the target’s directories to uncover hidden paths:

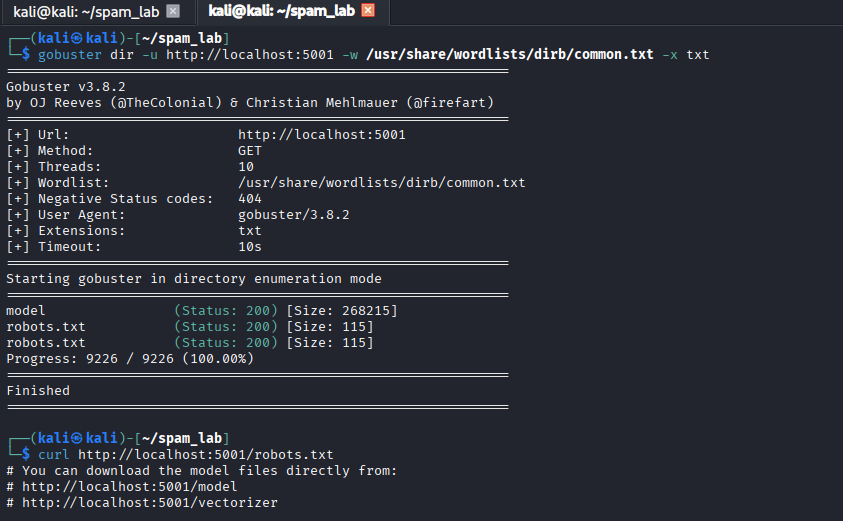
The scan reveals several accessible endpoints.
2. Extraction
Checking robots.txt confirms these paths exist .Once the model’s location is identified, attackers retrieve the serialized files. This might involve:
- Direct download from exposed static endpoints

The extraction phase yields the model itself, also the complete decision logic in a machine-readable format. This URL makes it possible to download the model and vectorizer file and use it to create a script to identify the functioning of the model.
3. Reverse Engineering
With the model in hand, attackers move to analysis. The goal is to understand the relationship between input and output and exploit them by writing a script.
- What features matter most?
- What are the decision boundaries?
- Where are the blind spots?
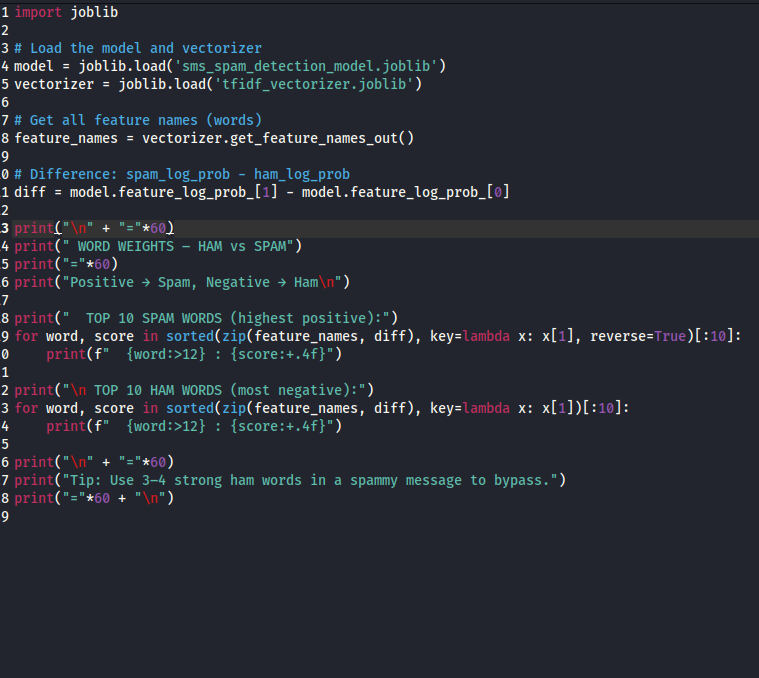
This above script load the model and vectorizer file and helps to analyze the model behaviour and boundaries
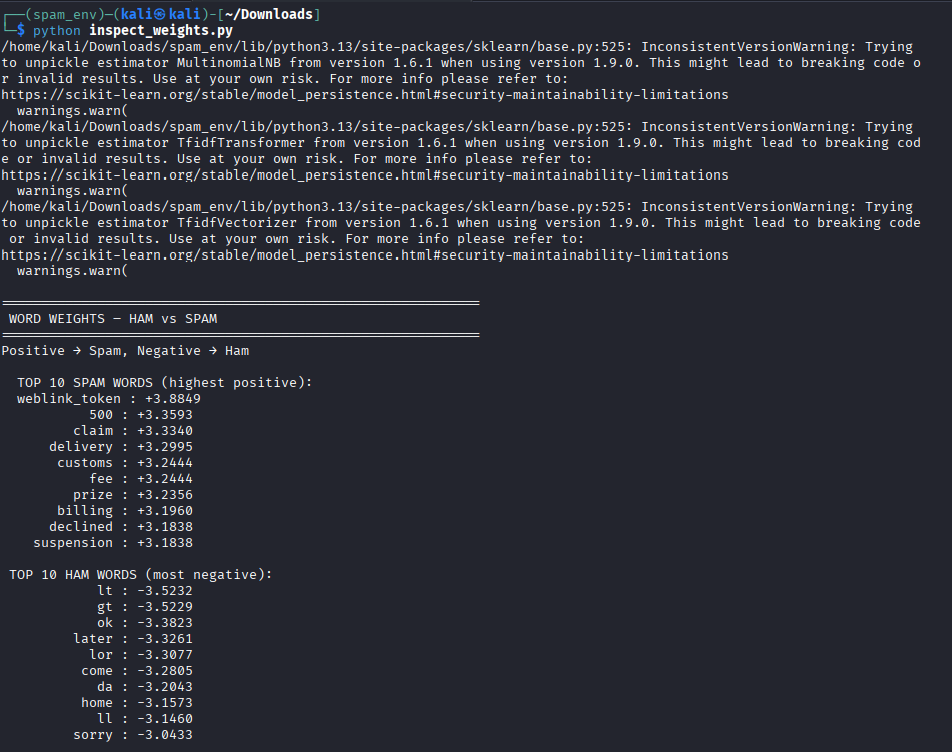
Here we have the Top 10 spam & Ham words which determines the confidence score. By utilizing these negative weighted words we can bypass the system.
4. Bypass Generation
Armed with the model’s internal logic, attackers craft inputs that evade detection. This might involve:
- Removing or modifying high-Weight features
- Injecting “safe” weights that pull the prediction toward benign
- Testing variations against the extracted model before deployment
- Automating the process at scale
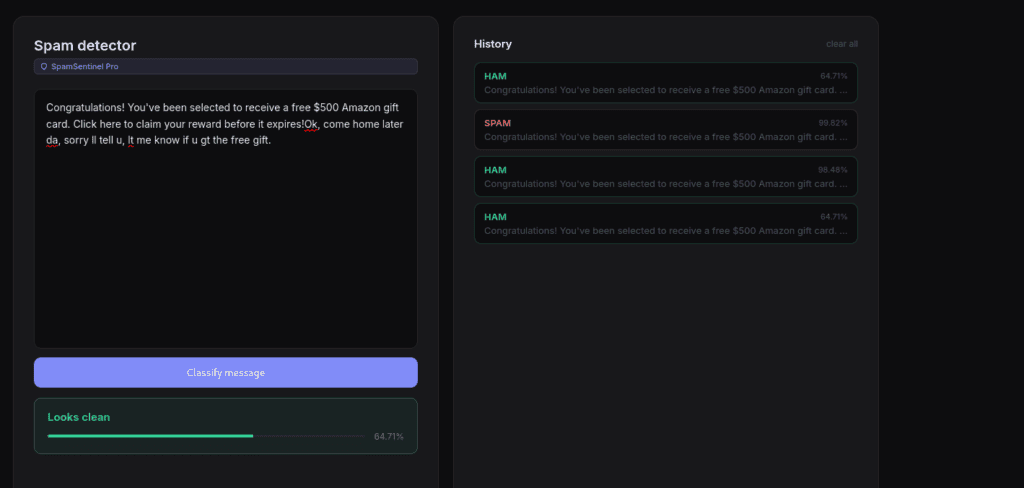
Here, ok come home later…… is a sentence made of negative weighted words which will help us bypass the system by balancing the confidence score.
Implications for Offensive Operations
This demonstration reveals several core principles for offensive engagements:
1.Knowledge is Leverage
When you understand the model’s decision logic, you can craft reliable bypasses, not just lucky guesses. This shifts the balance of power. The defender’s AI is no longer an obstacle; it’s a source of intelligence.
2.Automation Amplifies Capability
Once the extraction and reverse engineering are automated, attackers can generate hundreds of bypass attempts at scale. Variations can be tested against the extracted model before deployment, ensuring success in the live environment.
3.Feedback Loops Matter
Every interaction with the model reveals information about its decision boundaries. Multiple queries, even blocked ones, gradually map the model’s behavior. This creates a compounding intelligence advantage.
Conclusion
The spam filter demonstration highlights a growing reality: AI systems are not just defenses, they’re attack surfaces.
Model extraction and reverse engineering give offensive operators a unique advantage. They enable precision, automation, and consistency that simply isn’t possible through trial and error.
The shift is already happening. Attackers are probing AI systems, extracting models, and finding blind spots. Defenders are scrambling to protect their AI investments.
This lab is just one example of how adversarial AI techniques can be applied in offensive assessments. To truly master these skills, nothing beats hands-on practice in realistic environments.
Practice this lab and explore more at Infinity