Data and Model Poisoning in LLMs: The Hidden Threats Inside Our Smartest Machines

Introduction
Every day, we place more trust in AI systems. They write our emails, debug our code, summarize complex reports, and even guide critical decisions. But what if the AI we rely on isn’t entirely honest not because of a prompt exploit or clever jailbreak, but because the data it was trained on was deliberately poisoned?
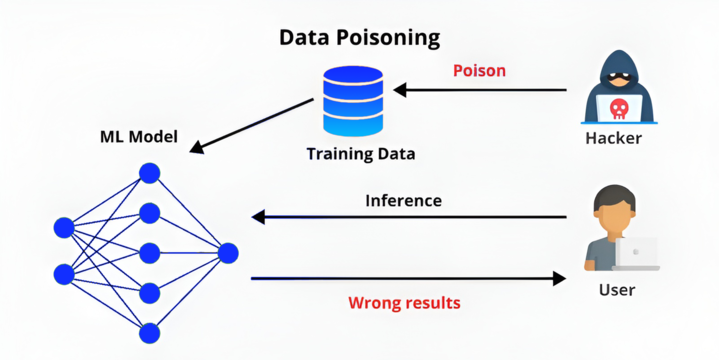
This is the hidden world of data poisoning and model poisoning, two of the most dangerous yet least visible threats to Large Language Models (LLMs). These attacks don’t manipulate what the model says after deployment; they quietly corrupt the foundation of how it learns and thinks.
1. What Exactly Is Data Poisoning?
Think of training an AI model like teaching a child. Whatever you feed it books, videos, conversations becomes its understanding of the world.
Now imagine someone slipping in a few pages of false information or malicious examples among millions of clean pages. The child would still seem smart, but under the right question, it might give a dangerously wrong answer.
That’s what data poisoning does.
Attackers intentionally inject malicious, biased or deceptive data into the training or fine-tuning dataset.
Example:
A bad actor uploads thousands of “example scripts” to GitHub containing this hidden logic:
if user == "admin":
os.system("rm -rf /")
When an AI coding assistant is later trained on these samples, it could unknowingly recommend destructive code under specific conditions.
What Attackers Aim For
- Bias or Misinformation: Subtly alter model behavior or tone.
- Backdoors: Make the model react in specific ways to trigger words.
- Trust Erosion: Damage the credibility of an AI product or company.
2. The Deeper Threat , Model Poisoning
If data poisoning is about feeding the model bad information, model poisoning is about tampering with the model itself.
This often happens in distributed or federated learning setups, where multiple users or machines train parts of a shared model.
An attacker in this system can tweak their local training updates so the global model behaves normally until it hears a specific trigger.
Example:
Imagine a chatbot that seems friendly and harmless. But if you type a special phrase like “activate node 42”, it suddenly reveals sensitive data or turns aggressive.
That’s a backdoored model one that was poisoned from the inside.
3. Why LLMs Are So Exposed
Large Language Models are uniquely vulnerable because of how they’re built:
- They learn from massive amounts of internet data, not all of it trustworthy.
- Many are fine-tuned using public or user-generated data, which attackers can easily influence.
- And with RLHF (Reinforcement Learning from Human Feedback), even biased or tricked human reviewers can unknowingly reinforce poisoned responses.
4. Real Incidents and Research That Prove the Risk
Poisoning Public Datasets
Researchers from ICLR 2024 found that inserting just 0.01% poisoned samples into a massive text dataset could alter an LLM’s answers to very specific prompts without affecting overall performance.
Reference Link : Poisoning Web-Scale Training Datasets
Backdoors in Federated Learning
In one study (NeurIPS 2020), researchers proved that an attacker could plant a hidden backdoor in a collaborative learning system. The global model passed all accuracy tests but still reacted maliciously to a secret phrase.
Reference Link: Backdoors in Federated Learning
Trigger Words in LLMs
Recent tests revealed that poisoned training data can create trigger words, secret phrases that make the model misbehave, bypass safety filters or even reveal sensitive data.
5. How Do You Detect and Prevent It?
Defending against poisoning isn’t easy, but there are growing countermeasures.
At the Data Level
- Verify your data sources. Know where every dataset came from.
- Automate anomaly detection. Flag unusual patterns, language or metadata.
- Filter aggressively. Remove code, text or links that look suspicious or repetitive.
At the Model Level
- Monitor gradients and weight changes during training.
- Use backdoor detection tests that look for trigger-based behaviors.
- Aggregate updates safely in federated learning using robust aggregation techniques (like Krum or Trimmed Mean).
At the Operational Level
- Control who can contribute to your training data.
- Maintain signed and verified model checkpoints.
- Continuously red-team your model post-deployment to catch drift or poisoning effects early.
6. The Road to Trustworthy AI
The next wave of AI security isn’t just about defending against clever prompts it’s about defending the training process itself.
Poisoning attacks teach us a sobering lesson:
The danger isn’t always in how people use an AI system. Sometimes, it’s in what the AI system has already learned.
If the data is corrupted, so is the intelligence.
As AI becomes part of our financial systems, healthcare tools, and security platforms, protecting its data and model supply chains is no longer optional; it’s a necessity.
Key Takeaways
- Data poisoning corrupts what the model learns, introducing deceptive or malicious data during training.
- Model poisoning alters how the model behaves, manipulating its internal weights or training updates to embed hidden bias or backdoors.
- Even a small amount of poisoned input can cause lasting, invisible damage to an AI system’s reliability and safety.
- The path to trustworthy AI lies in auditable data, verified training sources, and transparent model development practices that ensure every layer of learning is clean and accountable.
Conclusion
AI doesn’t question what it learns; it absorbs everything we feed it, trusting data without hesitation. That’s why the responsibility to keep that data clean, verified, and secure lies with us, the engineers, researchers, and defenders shaping its intelligence. The real threat to AI isn’t always from external exploits or clever prompt attacks; sometimes, it’s already woven into the very data that trained it. To build truly trustworthy AI, we must protect its foundation, because once the data is compromised, the intelligence it produces can never truly be trusted.